チューリングマシンの構成例。 チューリングマシン上の関数の適切な計算可能性
チューリング マシン (MT) は、抽象的な実行者 (抽象的なコンピューティング マシン) です。
アルゴリズムの組み合わせは、いくつかの与えられたアルゴリズムから新しいアルゴリズムを構築するための多くの特定の方法に対して確立された名前です。
アルゴリズムの組み合わせに関する定理は、アルゴリズムの一般理論の重要な部分を構成します。 一度証明されると、複雑で面倒なアルゴリズムを定義する回路を実際に書き出すことなく、後でその実現可能性を検証することが可能になります。
チューリング マシンのアルゴリズムの組み合わせは、チューリング マシンでの演算によって記述されます。
1.合成操作。
M 1 と M 2 を同じ外部アルファベット A« (a 0 ,a 1 ,...,a p ) を持つチューリング マシンとする。 それらの状態の集合をそれぞれ Q1 "(q 0,q 1,...,q n) および Q2 "(q 0",q 1",...,q m") と表すことにします。
意味。
マシン M 1 と M 2 の組み合わせは、M=M 1 ×M 2 で示されるマシンであり、そのプログラムはアルファベット A、状態の集合 Q« (q 0,q 1,...,q n,q) を持ちます。 n+1,...,q n+m) であり、次のようにマシン M 1 および M 2 のプログラムから取得されます。マシン M 1 のプログラムのどこにでも、記号 q 1 (マシン M 1 の最終状態)、シンボル q 0" (マシン M 2 の初期状態) に置き換えられます。マシン M 1 と M 2 のプログラム内の他のすべてのシンボルは変更されません (最終的には、残りは、マシン M のすべての状態の番号を付け直すことです: (q 0 ,q 1" ,q 2 ,...,q n ,q 0 " ,q 2" ,...,q m" ))。
この構成はマシン M 1 として「動作」し始めますが、マシン M 1 を停止する必要がある場合には、q 1 を q 0 に置き換えることにより、マシン M 2 のプログラムに切り替わります。合成操作は結合的ですが、可換的ではありません。
その動作は、マシン T1 と T2 の順次動作と同等です。
図は、n=1、m=1の重ね合わせ演算子を実装したチューリングマシンの構成を示しています。
写真1。
意味。
チューリングマシン M の反復をマシンと呼びます

2. 分岐操作。
M 1、M 2、および M 3 を、同じ外部アルファベット A« (a 0,a 1,...,ai,...,a j,...,ap) を持つチューリング マシンとし、したがって、状態: Q1 " (q 0 ,q 1 ,...,q n )、Q2 " (q 0 " ,q 1 " ,...,q m " )、Q3 " (q 0 " , q 1 " ,.. .,q l" )。
意味。
チューリング マシン M 1、M 2、および M3 にわたる分岐操作の結果はチューリング マシン M と呼ばれ、そのプログラムはマシン M 1、M 2、および M3 のプログラムから次のように取得されます。マシン M1 が書き込まれ、次にマシン M2 と M3 のプログラムが割り当てられます。 マシン M1 の最終状態 q 1 でシンボル a i が観察された場合、制御はマシン M2 に移されます。 シンボル q 1 がシンボル q 0" に置き換えられ、マシン M 2 が動作を開始します。マシン M 1 の最終状態 q 1 でシンボル a j が観察された場合、制御はマシン M 3 に転送されます。つまり、シンボル q 1 が置き換えられます。シンボル q 0" により、マシン M 3 が動作を開始します。 マシン M1 および M2 のプログラム内の他のすべてのシンボルは変更されません。 マシン M は、最終状態 q 1 で作業を完了します (結論として、マシン M の状態のエンドツーエンドの再番号付けを実行する必要があります)。
チューリング マシン M 1、M 2、および M3 での分岐演算の結果は次のように示されます。
2 文字のチューリング マシン (アルファベット 2 文字のチューリング マシン) の場合、任意のチューリング マシン M1、M2、および M3 での分岐操作は次のように表されます。

それらの。 マシン M1 が状態 q 1 で動作しているときにシンボル a 0 が観察された場合、制御はマシン M2 に転送され、そうでない場合はマシン M3 に転送されます。
3. ループ動作。
M をアルファベット A« (a 0 ,a 1 ,...,a p ) と状態の集合 Q« (q 0 ,q 1 ,...,q n ) を持つチューリング マシンとする。
意味。
ループ操作の結果はチューリング マシンと呼ばれ、(i=0,2,3,...,n; j=0,1,2,...,p; s=0,2, 3、...、n)
このプログラムは、コマンド q i a j ®q 1 a t r, rО(L,R,L), t=0,1,2,.. の結果の記号 q 1 を置き換えることによってマシン M のプログラムから取得されます。 .p、記号 q s が付いています。
2.4 チューリングマシンのバリエーション
チューリング マシン モデルは拡張できます。 任意の数のテープとさまざまな制限のある多次元テープを備えたチューリング マシンを考えることができます。 ただし、これらのマシンはすべてチューリング完全であり、通常のチューリング マシンによってモデル化されています。
このような等価性の例として、任意の MT を半無限テープ上で動作する MT に縮小することを考えてみましょう。
定理:どのチューリング マシンでも、半無限テープ上で実行される同等のチューリング マシンが存在します。
証拠:
Yu. G. Karpov の証明を考えてみましょう。 この定理の証明は建設的です。つまり、任意のチューリング マシンに対して、宣言されたプロパティを持つ同等のチューリング マシンを構築できるアルゴリズムを提供します。 まず、MT 作業テープのセルにランダムに番号を付けます。つまり、テープ上の情報の新しい場所を決定します。
写真1。
次に、セルの番号を付け直し、記号「*」が MT 辞書に含まれていないと仮定します。

写真1。
2.5 チューリングの計算可能性と決定可能性
再帰関数、チューリング マシン、または通常のマルコフ アルゴリズムを使用して計算可能な関数のクラスが一致することが上記で証明されました。 これにより、「計算アルゴリズム」という概念が記述方法に対して不変であると考えることができます。 違いは、アルゴリズム オブジェクトの使用においてのみ観察されます。 再帰関数の場合、オブジェクトが数値と数値関数であり、計算プロセスが重ね合わせ、再帰、最小化、反復の演算子によって指定される場合、チューリング マシンの場合、そのようなオブジェクトは外部メモリと内部メモリのアルファベットのシンボルであり、計算出口、遷移、ヘッドの移動などの処理をプロトコルで指定します。 通常のマルコフ アルゴリズムの場合、そのようなオブジェクトは単語またはシンボルのシーケンスであり、計算プロセスは、元のシンボルのシーケンスの構成と構造を目的の結果に変更する置換ルールまたは積によって指定されます。
算術 (数値) 関数は、値の範囲が集合 N の部分集合であり、その定義域が集合 N の要素である関数です。
アルゴリズムの問題の典型的な状況は、引数 x 1、x 2 の整数値に応じて、数値関数 f(x 1, x 2, ..., x n) を計算するアルゴリズムを見つける必要がある場合です。 , ..., x n。
関数の値を計算するために引数の任意の値のセットを許可する (または関数が特定のセットで定義されていないことを示す) アルゴリズムがある場合、関数 f:N n →N computable と呼びます。 計算可能関数の定義にはアルゴリズムの直観的な概念が使用されるため、「計算可能関数」という用語の代わりに「直観的計算可能関数」という用語がよく使用されます。 したがって、問題に対応する算術関数が直観的に計算可能であれば、質量問題には解決策があります。
関数 f(x 1 , x 2 , …, x n) は、与えられた値 k 1 , k 2 , …, k n 引数に対して関数 f(k 1 , k 2 , …, k n) 既存の機械的手順 (アルゴリズム) を使用します。
アルゴリズムの概念を明確にする代わりに、「計算可能な関数」の概念を明確にすることを検討できます。 通常、それらは次のスキームに従って進行します。
1. 正確に定義された関数のクラスが導入されます。
2. このクラスのすべての関数が計算可能であることを確認します。
3. 計算可能な関数のクラスが導入された関数のクラスと一致するという仮説 (テーゼ) を受け入れます。
関数を計算するアルゴリズムがある場合、その関数は計算可能と呼ばれます。 「計算可能性」はアルゴリズム理論の基本概念の 1 つであり、計算される関数やアルゴリズムに対して不変です。 計算可能な関数とアルゴリズムの違いは、関数の説明と、独立した引数の値を考慮してその値を計算する方法の違いです。
チューリングの論文。 チューリング マシンを使用すると、直感的なアルゴリズムを実装できます。
チューリングの理論から、アルゴリズムの問題が発生した場合、チューリング マシンの構築、つまり十分に形式化されたアルゴリズムの概念に基づいて問題を解決する必要があることがわかります。 さらに、アルゴリズムの問題では、アルゴリズムの構築についてではなく、特別に構築された関数の計算可能性について話していることがよくあります。
このような場合、アルファベット (0,|) を使用すれば十分であることに注意してください。0 は空文字です。 たとえば、0 を含む自然数は、このアルファベットで次のようにエンコードされます。 1 - ||; 2 -
N - ||…| (n + 1 回)。 部分数値 n ローカル関数 f(x1, x2, ..., xn) は、次の意味で計算するマシン M が存在する場合、チューリング計算可能と呼ばれます。 1. 引数値のセットの場合
自己適用の問題
チューリングマシンの定義によれば、これはトリプルです。 T=
P: 気ある あ、jある ® qrある としてある セントある 、a = 1、2、…、k 、 どこ S1- R、 S2-L, S3- C . (*)
この場合、いくつかの共通のアルファベットがあると仮定できます。 あ0そして Q0、文字が書かれている ある そして q すべてのチューリングマシンに対応。 それから記号 気ある, あ、jああ、 qrある, としてある, セントあるアルファベットの記号です あ0そして Q0.
このアプローチにより、すべてのチューリング マシンに番号を付けることができます。つまり、各マシンには、このマシンに固有の特定の番号 (コード) が割り当てられ、それによって他のマシンと区別できます。 ここでは、番号付け方法の 1 つを検討します。
チューリング マシンのゴデル式番号付け。 させて p1、p2、p3 , ... - 昇順に並べられた一連の素数 (2、3、5、7、11、13、... など)
プログラム付きチューリングマシン番号 (*)着信番号
n(T) = .
例
機能を実装するマシン S(バツ)= x + 1 、アルファベットのプログラムがあります {0, } 。 という事実を考慮したこのプログラムの数 0 = 0 , 1= | 数字があります:。
n(T)= 2 1 3 1 5 1 7 1 11 1 13 1 17 0 19 0 23 1 29 3 。
明らかに、すべての自然数がチューリング マシン数であるわけではありません。 一方、次の場合は、 n – 特定のマシンの番号 (通常はアルファベット) であれば、そのプログラムはこの番号から一意に復元できます。
車 T、という単語に当てはまります n(た)(つまり、自分の番号のコードに)、 自己適用と呼ばれる .
自己適用可能なマシンと非自己適用可能なマシンの両方を構築することが可能です。 たとえば、指定された例のマシンは自己適用可能です。 車 T、プログラムの右側の部分 (表の本文) に停止記号がなく、どの単語にも適用できないため、単語にも適用されません。 n(た).
自己適用問題は次のとおりです。任意のチューリング マシンが与えられた場合に、それが自己適用可能かどうかを決定するアルゴリズムを示します。
チューリング理論によれば、そのようなアルゴリズムはチューリングマシンの形で求められるべきである。 このマシンはすべてのチューリング マシンの数値コードに適用できる必要があり、テスト対象のマシンのコードの処理結果に応じて、異なる最終構成が得られます。
たとえばこの車を考えてみましょう Tコードに適用される n(T * ) 。 車なら T * 自己適用、その後最終的なマシン構成 Tのように見える ああ」 q0 | B」、そして車の場合 T * 自己適用できない場合、マシンの最終構成 Tのように見える ああ」 q0 0B ". ここ a"、B"、a"、B"- 言葉。
定理自己適用性問題はアルゴリズム的に決定不可能です。つまり、上記の意味でこの問題を解決するチューリング マシンは存在しません。
定理から、一般的なアルゴリズムは存在しないことがわかります。 問題解決者自己適用性。 特定の特殊な場合には、そのようなアルゴリズムが存在する場合があります。
この定理の結果を使用して、最初の単語への適用可能性の問題の決定不可能性を証明しましょう。
頭語の適用性の問題 は次のとおりです: マシンに従ってアルゴリズムを作成します。 Tそしてその言葉 バツ インストールする、該当するマシン Tところで バツ そうでない場合(そうでない場合は、停止の問題が発生します)。
チューリング マシンの観点から見ると、自己適用性問題の定式化と同様に、この問題は次のように定式化されます。次の形式のすべての単語に適用できるマシンを構築することは可能ですか? n(T)0 バツ 、 どこ T任意のマシン、 バツ – 任意の単語、およびマシンの場合 Tという言葉に当てはまる バツ ああ」 q0 |B" , そして車の場合 Tその言葉には当てはまらない バツ 、最終的な構成につながります ああ」 q0 0B」 . ここ a"、B"そして a"、b"- 任意の言葉。
定理最初の単語への適用性の問題はアルゴリズム的に決定不可能です。つまり、上記の意味でこの問題を解決するチューリング マシンは存在しません。
自己適用性の問題について上で述べたように、最初の準備ステップは番号付けです。 したがって、以下では、アルゴリズムとその 3 つの主要なタイプのアルゴリズム モデルについて、この問題を一貫して検討し、解決します。
アルゴリズムの番号付け
アルゴリズムの番号付けが役割を果たします 重要な役割彼らの調査と分析では。 任意のアルゴリズムは有限単語 (あるアルファベットの記号の有限シーケンスとして表される) として指定でき、有限アルファベット内のすべての有限単語のセットは可算であるため、すべてのアルゴリズムのセットも可算です。 これは、自然数のセットとアルゴリズムのセットの間に 1 対 1 のマッピングが存在すること、つまり、各アルゴリズムに数値を割り当てる機能が存在することを意味します。
アルゴリズムの番号付けは、アルゴリズムで計算可能なすべての関数の番号付けでもあり、どの関数も無限の数を持つことができます。
番号付けの存在により、数値と同じ方法でアルゴリズムを操作できるようになります。 番号付けは、他のアルゴリズムと連携して動作するアルゴリズムを研究する場合に特に役立ちます。
初期オブジェクト X のセットと目的のオブジェクト Y のセットに関する特定の質量問題があるとします。質量問題の解が存在するためには、セット X と Y の要素が構成的なオブジェクトである必要があります。 したがって、これらのセットの要素には自然数で番号を付けることができます。 x∈ X を初期オブジェクトとし、その数を n(x) で表します。 元のオブジェクト x に対する質量問題で、数値 n(y) の目的のオブジェクト y∈ Y を取得する必要がある場合、f(n(x))=n となる算術関数 f: Nn →N を定義します。 (y)。
質量問題の算術関数を構築する例として、質量問題を考えてみましょう。
1. 自然数の配列 ] が与えられた場合、自然数 2x1, 3x2,... p(n)xn を割り当てることができます。ここで、p(n) – n番目の素数番号。 長さ 5 の配列の例を見てみましょう。
] 2x13x25x37x411x5。
この番号付けは、算術関数 f を定義します (たとえば、f(73500) = f(22315372110) = 20315272113 = 4891425)。
2. あらゆる有理数には何らかの自然数があります。 問題に必要なオブジェクトのセットの番号付けは簡単です。
(「はい」、「いいえ」) a (1, 0)。 特定の質量問題に対して、前の例の手法を使用して 1 つの引数の算術関数を構築することも、3 つの引数 (元のトリプルの要素の 3 つの数) の関数を検討することもできます。
3. プログラム テキストの番号付けは次のように実行できます。どのプログラムでも、256 進数体系で数値を記録していると認識できます (プログラムの記録に ASCII テーブル文字が使用された場合)。
質量問題から算術関数への移行により、質量問題に対する解の存在の問題を存在の問題に還元することができます。 効果的な方法算術関数の値をその引数から計算します。
数値セットの番号付け
アルゴリズムの理論では、複数の変数の関数の研究を 1 つの変数の関数の研究に減らすことを可能にする手法が普及しました。 これは、数値の集合の番号付けに基づいており、数値の集合とその数値の間には全単射の対応があり、数値の集合からその数値を決定する関数、および数値の集合自体の数値からその数値を決定する関数は一般に再帰的です。 たとえば、2 つの独立変数 (x, y) を含む関数の場合、このマッピング h(x, y) は次のようになります。
写真1。
ペア (x, y) が部分的に順序付けされたセット N(2) を形成するとします。 h(x, y) = n とすると、逆マッピングが行われます: x = h -1 1 (n) および y= h -1 2 (n)、つまり h(h -1 1 (n), h -1 2 (n)) = n。 これにより、任意のペア (x, y) の数値 n を計算したり、逆に数値 n を使用して x と y の値を計算したりすることができます。

これらのルールを使用すると、トリプルの番号付け h 2 (x, y, z) = h(h(x, y), z) = n を計算でき、逆に、トリプルの数によって、次の値を計算できます。 x、y、z。 たとえば、h 2 (x, y, z) = n の場合、z= h -1 2 (n)、y= h -1 2 (h -1 1 (n))、x= h -1 1 ( h -1 1 (n))、h 2 (x、y、z) = h(h(h -1 1 (h -1 1 (n))、h -1 2 (h -1 1 (n)) )、h -1 2 (n))。 トリプル (x, y, z) は、部分的に順序付けされたセット N(3) を形成します。 同様に、任意の数の数値については次のようになります。
h n-1 (x1, x2,…, xn)=h(h…h(h(x1, x2), x3)… x n-1), xn)。 h n-1 (x1, x2,…, xn)=m の場合、xn = h -1 2 (m)、x n-1 =h -1 2 (h -1 1 (m))、... ................................................、x2 = h -1 2 (h -1 1 (. .. h -1 1 (m)...))、x1 = h -1 2 (h (...h (m)...))。
集合 N (1) 、 N (2) 、...、 N (i) 、...、 N(n の番号付けを持ち、ここで N (i) は数値の集合 (i) です。任意のセット番号 M = N (1) N (2) ... N (i) .. N(n) を組み合わせた番号付けを確立することができます。ここで、M N です。任意の n N に対して、 h(x1, x2,..., xn )= h(h n −1 (x1,x2,..., xn), n −1)。
h(x ,1x ,2..., x)n = m の場合、 h n−1 (x ,1x ,2..., x)n = h -1 1 (m)、n= h -1 2 (m)+1。 上記の式を使用すると、x1、x2、…、xn の値を復元できます。
関連情報。
チューリングマシンの定義、操作、指定方法
チューリング マシンは、次の部分から構成される特定の仮想 (抽象) マシンとして理解されます (図 3.1)。
1) 両方向に無限に伸びるテープ。セルに分割されており、各セルにはアルファベットから 1 文字だけと空の文字 l だけを書くことができます。
2) 制御デバイス (作業ヘッド)。いつでもセットのいずれかの状態になることができます。 各状態では、頭がセルの反対側に配置され、アルファベットから文字を読んだり (レビュー) したり、書いたりすることができます。 あ.
米。 3.1. チューリングマシン
MT の機能は、一連の基本ステップ (サイクル) で構成されます。 各ステップでは次のアクションが実行されます。
1. 作業ヘッドがシンボルを読み取り (レビュー) ます。
2. ヘッドの状態と監視対象のシンボルに応じて、ヘッドはシンボルを生成し、それを監視対象のセルに書き込みます (おそらく =)。
3. ヘッドが 1 セル右に移動します (R)、 左 (左)またはそのままの状態で (ホ);
4. ヘッドは別の内部状態になります。 (おそらく=)。
この状態は初期および最終と呼ばれます。 最終状態に入ると、機械は停止します。
MT の完全な状態は次のように呼ばれます。 構成 。 これは、テープのセル間の文字の分布、動作ヘッドと監視対象のセルの状態です。 構成はそのまま tは次の形式で記述されます。 は監視対象のセルの左側のサブワード、 は監視対象のセル内の文字、 は右側のサブワードです。
初期構成と最終構成は標準と呼ばれます。
MT の動作を記述するには 3 つの方法があります。
フォームのコマンド体系
機能テーブル。
遷移のグラフ(図)。
例を挙げて見てみましょう。
例1.アルファベットの 2 つの単語の連結を実装する MT を構築します。 テープ上の単語は * で区切られています。 初期設定は標準です。
MT コマンド システムは次のようになります。
この状態でヘッドが空シンボルまで右に移動します。
右端の文字が消去されます。
最初の単語が空の場合、アスタリスクは消去されます。
右側の単語が 1 文字ずつ左に 1 位置ずつシフトされます。
標準の最終構成に移行します。
機能表
| ある | b | * | 私 | |
| - | ||||
| - | ||||
| - | ||||
| - |
表内のダッシュは、記号 l が州に見つからないことを意味します。
|
|
|||
標準の最終構成。
MT 上の辞書関数の計算は次のように理解します。 初期構成でテープに単語 a を書き込むとします。 値が決定されると、有限のステップ (サイクル) 数で、マシンは最終構成に移行し、単語がテープに書き込まれる必要があります。 それ以外の場合、MT は無期限に動作するはずです。
MT を使用すると、数値に対する算術演算のパフォーマンスを記述することができます。 この場合、数字は、ある記数体系の数字で構成されるアルファベットの単語としてテープ上に表示され、このアルファベットに含まれない特殊な記号 (* など) で区切られます。 最も一般的に使用されるシステムは単項であり、単一の記号 –1 で構成されます。 テープ上の数字 X は、アルファベットの単語 (または省略形) で書かれています。 A=(1).
= の場合に構成を構成にマッピングする MT が存在する場合、数値関数は適切に計算可能 (または単にチューリング計算可能) です。 y、または未定義の場合は無期限に実行されます。
例2。単項コードで 2 つの数値を加算する演算。
初期設定:
最終構成: つまり 足し算は実際には数値を割り当てることになります b番号に ある。 これを行うには、最初の 1 が消去され、* が 1 に置き換えられます。
MT を機能表の形式で説明します。
| * | 私 | ||
| - | |||
| - | |||
| - |
MT を記述するための上記の方法は、実際には単純なアルゴリズムにのみ使用できます。 複雑なものの場合、説明が煩雑になります。 同様に、最も単純な関数と重ね合わせ、原始再帰、最小化の演算子だけを使用して再帰関数を記述するのは非常に面倒です。 したがって、関数の原始的または部分的な再帰性は、原始的または部分的な再帰性がすでに証明されている他の関数を使用して証明されます。
同様に、複雑なアルゴリズム用のチューリング マシンは、既存の MT を使用して構築できます。 この構成をMT構成と呼びます。
MT 合成の 4 つの主な方法について説明します。
連続合成(重ね合わせ)。
並列構成。
分岐
連続合成 マシンとコンピューティング辞書関数とアルファベット あ、車と呼ばれる T、関数を計算します。 一連の構成は次のように表されます。
と指定されています。
逐次合成は通常、アルゴリズムの線形セクションを記述するために使用されます。
機械の構築の可能性に関する定理の証明 T、これは 2 つの任意のマシンの逐次合成であり、最終状態を初期状態と識別することによって実行されます。
例 3.単語 a を単語 a*a に変換するコピー マシンと加算マシンを使用して、単項コードで 2*X 乗算アルゴリズムを構築します。 必要な MT は次のようになります。
| | | |
|||||||||||||
| | |
||||||||||||||
並列構成 マシンとコンピューティング 辞書関数とアルファベット あそして でしたがって、マシンは次のように呼ばれます。 T、辞書関数を評価します。 ここで、記号は並列 MT 合成で単語を区切るために使用されます。
| |
と指定されます: 。
実際、2 つの MT の並列構成は、異なるアルファベットの 2 つの単語で構成される単語を入力として受け取り、2 つの単語で構成される単語を出力します。 は、同時に独立して動作する 2 台の機械を表します。
並列構成を実現するには、2 階建てのベルトを備えた機械が使用されます。 これが必要なのは、計算と時間が連続して行われ、たとえば最初に計算されると、a よりも多くのスペースが必要となり、単語 b が損なわれる可能性があるためです。 2 階建てのテープ マシンは次のように動作します。単語 b は 2 階に書き込まれ、1 階で消去され、1 階で計算され、2 階で計算されて、おそらくシフトを伴って 1 階に書き換えられます。 。
並列合成を実装するには n使用される機械 n–床テープ。
2 階建てテープの MT コマンドは次のように記述されます。 は 1 階と 2 階にそれぞれ書かれた文字です。
例 4。 マシンと 2 進数システムの計算関数の並列構成を実装し、 a+b単項システムでは。
入力単語の形式は次のとおりです。
コマンド体系を使用して MT の動作を説明しましょう。
単語 b に右に移動
単語 b を 2 階に書き換える
左に移動して単語 a
数値 X に 1 を加えます。
単語 b に右に移動します。
国勢調査 b を 1 階に同時追加 あるそして bそれに応じて.T。 中括弧内のコマンドがコマンド システムに追加されました
MT全体の最終状態。
すべての場合において、アルゴリズムの開始時に、ソース データの特別な値 (ほとんどの場合 0) のチェックを挿入する必要があることに注意してください。この要件に従わない場合、ループが発生する可能性があります。
MT 合成を使用して、複雑なアルゴリズムを構築できます。 どのようなアルゴリズムも MT 構成として実装できるのでしょうか?という疑問が生じます。 この質問に対する答えは次のとおりです。 チューリングの論文 、チャーチの理論の類似物: すべてのアルゴリズムはチューリング マシンを使用して実装でき、その逆も同様で、チューリング マシンによって実装されるすべてのプロセスはアルゴリズムです。
チューリングの理論は定理ではありません; それを証明することは不可能です。 これには非公式の概念が含まれています。」 アルゴリズム」 しかし、長年にわたる数学的実践により、この命題は確実に裏付けられています。50 年間、チューリング マシンを使用して実装できない直感的な意味でのアルゴリズムは見つかっていません。
仕事の目標:チューリング マシンの構成を使用してアルゴリズムを作成する実践的なスキルを習得します。
理論情報
MT を記述するための上記の方法は、実際には単純なアルゴリズムにのみ使用でき、そうでない場合は記述が煩雑になります。 複雑なアルゴリズム用のチューリング マシンは、既存の基本 MT を使用して構築でき、この構築はと呼ばれます。 構成MT.
MT 合成の 4 つの主な方法について説明します。
連続合成(重ね合わせ)。
並列構成。
分岐
1. チューリングマシンの逐次構成
連続合成または 重ね合わせチューリングマシンや 
 そして
そして  アルファベットで あ、それは車と呼ばれています M、関数を計算します
アルファベットで あ、それは車と呼ばれています M、関数を計算します  .
.
一連の構成は次のように表されます。
![]()
そして指定されている  または
または  .
.
2. チューリングマシンの並列構成
並列構成
車  そして
そして  、辞書関数の計算
、辞書関数の計算  そして
そして  アルファベットで あそして で、したがって、マシンは次のように呼ばれます。 M、辞書関数を評価します。 ここに標識があります
アルファベットで あそして で、したがって、マシンは次のように呼ばれます。 M、辞書関数を評価します。 ここに標識があります  並列 MT 合成で単語を区切るために使用されます。
並列 MT 合成で単語を区切るために使用されます。
並列構成MT  そして
そして  は次のように描かれています。
は次のように描かれています。

そして指定されています:  .
.
実際、2 つの MT の並列構成は、異なるアルファベットの 2 つの単語で構成される単語を入力として受け取り、同じく 2 つの単語で構成される単語を出力します。 は、同時に独立して動作する 2 台の機械を表します。 並列構成を実現するには、2 階建てのベルトを備えた機械が使用されます。
ダブルデッキベルトマシンは次のように動作します。
1) 単語  テープの2階で書き換えられ、1階で消去され、
テープの2階で書き換えられ、1階で消去され、
2) 計算された 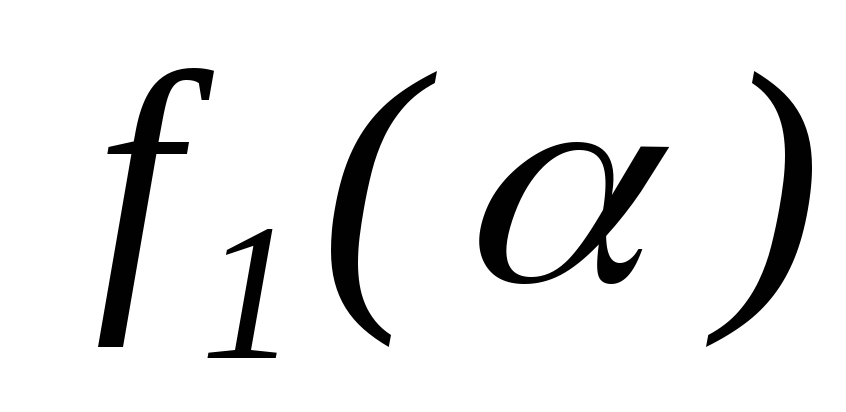 1階に、
1階に、
3) 計算された  二階にあります
二階にあります
4)
 おそらくシフトを伴って 1 階に書き直されました。
おそらくシフトを伴って 1 階に書き直されました。
2 層テープを使用した MT コマンドは次のように記述されます。
 ,
,
どこ  – 1階と2階にそれぞれ書かれた手紙。 単語の長さを表してみましょう
– 1階と2階にそれぞれ書かれた手紙。 単語の長さを表してみましょう  、 それぞれ、
、 それぞれ、  .
.
2 階建てのテープを使用してチューリング マシンの動作を実証してみましょう。 一般に、単語の長さは、  そして
そして  は互いに一致しませんが、イメージを簡単にするために、それらが等しいと仮定します。 次に、2 階建てテープを使用した MT でのポイント 1) ~ 4) の実装は、次のように実行されます。
は互いに一致しませんが、イメージを簡単にするために、それらが等しいと仮定します。 次に、2 階建てテープを使用した MT でのポイント 1) ~ 4) の実装は、次のように実行されます。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|





















|
|
|
|
|
|
|
|
|
|
|
|
|
|












|
|
|
|
|
|
|
|






|
|
|
|
|
|
|
|






並列合成を実装するには n チューリングマシンが使われている n– 床テープ。
3. チューリングマシンの構成における分岐または条件遷移
チューリングマシンが与えられた場合  そして
そして  、辞書関数の計算
、辞書関数の計算  そして
そして  、そして車
、そして車  、いくつかの述語を評価します P(
)
復元あり(単語を消さずに)
),
その後、チューリング マシンを構築して分岐を実装できます。
、いくつかの述語を評価します P(
)
復元あり(単語を消さずに)
),
その後、チューリング マシンを構築して分岐を実装できます。  、関数を計算します。
、関数を計算します。

構成図におけるチューリング マシンの分岐は次のように表されます。

そして指定されている  、 ここ
、 ここ  - 機械の動作の結果
- 機械の動作の結果  、述語の場合は値「1」を受け取ります P(
)=
”真実”
述語の場合は「0」 P(
)=
“間違い”
,
、述語の場合は値「1」を受け取ります P(
)=
”真実”
述語の場合は「0」 P(
)=
“間違い”
,
 – 入力単語のコピーを実装するチューリングマシン
– 入力単語のコピーを実装するチューリングマシン  .
.
4 . チューリングマシンの構成におけるサイクル
サイクル構成では、MT は分岐と同じ原理に従って実装されます。
" さよなら P(
)=
”真実”
、 満たす  »,
»,
どこ
– 最初の実行前にテープ上の単語  そして次の実行後 .
そして次の実行後 .
サイクルを表すために、いくつかの表記法を導入します。
 – 述語の計算を実装するチューリング マシン P(
)
;
– 述語の計算を実装するチューリング マシン P(
)
;
 –MT、入力単語のコピーを実装します。
–MT、入力単語のコピーを実装します。  ;
;
 –MT、ループ内で実行され、実装されます。
–MT、ループ内で実行され、実装されます。  ;
;
 –MT、ループを抜けて実装するときに実行されます。
–MT、ループを抜けて実装するときに実行されます。  .
.
次に、チューリング マシンの周期的な構成、つまりサイクルは次のように表すことができます。

チューリングマシン構成を使用したプログラミング:
1) ブロックが基本 MT に対応するような詳細レベルの複雑なアルゴリズムのブロック図の構築。
2) 単純なブロックを実装する基本 MT の構築。
3)基本MTを組み合わせてMT構成にする。
例。を実装する MT コンポジションを構築する  .
.


 – 入力単語のコピーを実装するチューリング マシン。
– 入力単語のコピーを実装するチューリング マシン。
 –MT、定数ゼロを設定する機能を実装します。
–MT、定数ゼロを設定する機能を実装します。
 –MT、復元を伴う述語の計算
–MT、復元を伴う述語の計算  ;
;
 – 選択機能を実装したMT
– 選択機能を実装したMT  -その議論から
-その議論から  引数。
引数。
 –MT、引数削減機能を実装
–MT、引数削減機能を実装  単項コードでは 1 ずつ (左端の文字を消去)。
単項コードでは 1 ずつ (左端の文字を消去)。
 – MT。単項コードで 2 つの数値の加算を実行します。
– MT。単項コードで 2 つの数値の加算を実行します。
いずれの場合も、アルゴリズムの実行開始時に入力データの正しさをチェックする必要があることに注意してください (たとえば、除算中の引数が 0 に等しいかどうか)。
図1.6
図 1.6 では次の表記が使用されています。
T 1、T 2 - チューリング マシン。
ST 1、ST 2 - それぞれマシン T 1 および T 2 のコマンド システム。
x - マシン T 1 の初期情報。
T 1 (x) - マシン T 1 の操作の結果。
T 2 (T 1 (x)) - マシン T 2 の操作の結果。
例として、2 台のマシンの構成を考えてみましょう。1 台目はコピー操作を実行し、2 台目は単項コードで数値を加算する操作を実行します。 マシンの組み合わせの図と、得られた結果を含むテープの例を図 1.7 に示します。

図1.7
図 1.7 に示す構成では、既知の複写機や加算機を使って数値を 2 倍にする演算を実行できます。 したがって、一連の特定の演算 (算術演算など) を解決するためのチューリング マシンのアルゴリズムを構成した後、より複雑な問題を解決するためのチューリング マシンの構成を構成できます。 この場合、一般的なアルゴリズムの開発は、チューリング マシンで実行するアルゴリズムがすでに知られている操作からコンパイルすることになります。 このアプローチは、プログラミングにおけるプロシージャや関数の使用に似ています。
ただし、マシン合成を使用するには、基本的な演算を実行するためのアルゴリズムが既知であり、そこから一般的なアルゴリズムが構成されることが前提となります。 したがって、任意の問題を解決する場合、このアプローチでは、新しいアルゴリズムを作成し、それに応じて異なる制御ユニットを備えたチューリングマシンを開発する必要性が排除されません。 汎用チューリングマシンを使用することで、制御ユニットの構造を変更することなく任意のアルゴリズムを実装することが可能です。
1.2.2.ユニバーサルチューリングマシン
何らかのチューリング マシンが与えられている場合 (つまり、入力、出力信号、および状態のアルファベット、ヘッドの初期位置とマシンの初期状態がわかっているほか、マシンの動作のテーブルと初期情報が記録されたテープがわかっている場合) ) の場合、このマシンが意図しているすべての情報変換を段階的に手動で実行できます。 実際、この場合、チューリングマシンのシミュレーションが実行されます。
チューリング マシンのモデル化時に実行される操作を分析すると、モデリングは最終的に各ステップで次のアクションを繰り返すことになることがわかります。
Äヘッドが置かれているテープセルから文字を読み取ります。
Äマシン操作テーブルでコマンドを検索します。 検索は、マシンの現在の状態と読み取られたシンボルの値に基づいて実行されます。
Äテープに書き込むコマンドからシンボルを選択し、記録します。
Äコマンドからヘッド移動シンボルを選択して移動します。
Ä コマンドから新しいマシン状態を選択し、現在の状態を新しい状態に変更します。 その後、次のステップに進み、これらのステップを繰り返します。
|
|
 |
|||||
 |
|||||
図1.8
これらの基本的なアクションの性質は、元のマシンの動作をシミュレートする他のチューリング マシンを使用してすべてを実行できるようなものです。 モデリングの本質は図 1.8 で説明されています。
マシン T がコマンド システム ST を持ち、情報 X を含むテープを処理する場合、その動作は、独自のコマンド システム SU を持つ別のマシン U によってシミュレートできます。 マシン U の入力をシミュレートするには、情報 X を含むテープを提出するだけでなく、 , コマンドシステム(作業テーブル)STも含まれます。 このコマンド体系は、元の情報と同じテープに記録することができます。
 |
図1.9
重要な機能モデリング マシンの特徴は、そのコマンド システム SU (およびそれに応じて制御ユニットの構造) が、シミュレートされたマシン T の動作アルゴリズムに依存しないことです。他のチューリング マシンの動作をシミュレートできるチューリング マシンは、ユニバーサルと呼ばれます。 ユニバーサル チューリング マシン (UMT) の構造の変形例を図 1.9 に示します。
UMT テープは、データ ゾーン、モード ゾーン、コマンド ゾーンの 3 つのゾーンに分割されています。
データ ゾーンには、シミュレートされたチューリング マシンによって処理される必要がある初期情報が含まれています。 同じゾーンに、UMT 操作の結果が記録されます。
モード ゾーンは、現在の状態 Q t と、特定のサイクルでデータ ゾーン セルから読み取られる現在の入力シンボル X t を記録します。
コマンド ゾーンには、シミュレートされたマシンのコマンド システムが含まれています。 コマンドはグループに編成されています。 最初のグループには記号 Q 0 で始まるコマンドが含まれ、2 番目のグループには記号 Q 1 などで始まります。 各グループ内で、コマンドはシンボル X t の値によって順序付けされます。 したがって、テープ上のコマンドは、シミュレートされたマシンの動作テーブルに配置されているのと同じように配置されます。
テープからの情報の読み取りとテープへの書き込みは、G d - データ ヘッド、G r - モード ヘッド、G k - コマンド ヘッドの 3 つのヘッドを使用して実行されます。 各ヘッドはベルトの独自のゾーンに沿って移動できます。
UMT が動作を開始する前に、関連情報をテープの各ゾーンに記録する必要があります。 ヘッドは各ゾーンの左側のシンボルの上に取り付ける必要があります。
UMT の動作はサイクルで発生し、各サイクルでシミュレートされたマシンの 1 つのコマンドの実行がシミュレートされます。 UMT の動作グラフを図 1.10 に示します。
 |
図1.10
図 1.10 では次の表記が使用されています。
Q G to P (G to L、G r P、G r L、G d P、G d L) - ヘッドの 1 つを移動します。
右か左;
Q (G k)、(G d)、(G r) - ヘッドの 1 つによって読み取られた情報。
Q (G k) à (G r) - コマンドヘッドによるデータの読み取りとこのデータの書き込み
モードヘッドを使用してテープモードゾーンに転送されます。
Q a は値 1 を取る補助変数です。
頭部 Гк と Гр によって読み取られる文字が一致するかどうか。
Q in は値 1 を取る補助変数です。
現在の状態 (Q t) と最終状態 (Q z) のシンボルが一致するかどうか
Q p - コマンドが先頭の場合に値 1 を取る信号
左への移動は指揮区域の境界を越えた。
UMT の動作の各サイクルでは、次の手順が実行されます。
コマンドゾーンを検索します。
ゾーン内でチームを検索します。
コマンド実行のシミュレーション。
コマンド ゾーンの検索は、モード ゾーンからの現在の状態 Q t とコマンド ゾーンの最初のコマンドの開始時に記録された状態 Q i を比較することで始まります。 これらの状態が等しくない場合、コマンド ヘッドは次のコマンドの先頭に移動し、ヘッドの 5 ステップが右に実行されます (状態 U 0 ~ U 4)。 シンボル Q t と Q i が一致する場合、コマンドの先頭は目的のゾーンの最初のコマンドの先頭にあります。 次に、モード ゾーンの Q t および X t シンボルに対応するコマンドの検索が開始されます。 これを行うには、モード ヘッドがモード ゾーンのシンボル X t の上に配置され、コマンド ヘッドが現在のコマンドのシンボル X i の上に配置されます。
ゾーン内のコマンドの検索は、コマンド ゾーンの検索と似ています。 この場合、文字 X t と X i が比較されるまで、コマンド ヘッドは右に 5 ステップ (状態 U 5 ~ U 9) に移動します。
コマンドの実行(状態 U 10 ~ U 17)は、コマンド ヘッドを 1 ステップ右に移動することから始まり、その後、見つかったコマンドから読み取られたシンボル Y t が、コマンドの代わりにデータ ヘッドを使用してデータ ゾーンに書き込まれます。以前に読み取られたシンボル X t 。 コマンドヘッドの次のステップを右に進めた後、見つかったコマンドからデータヘッド移動シンボル(Y・d)を読み取り、このシンボル(R、L)に従ってデータヘッドを移動する。 その下には、次に処理されるシンボル (X t +1) があり、モード ヘッドを使用して、次のサイクルを準備するためにモード ゾーンに書き込まれます。 次に、次の状態 Q t +1 (状態
U14、U15)。 状態U16では、解決を終了するための条件がチェックされる。 次の状態のシンボルがモデル化されたマシン (Q z) の最終状態のシンボルと一致しない場合、問題の解決は完了せず、状態 U 17 でコマンド ヘッドは元の位置に移動します (最初のゾーンの最初のコマンドの先頭まで)。 この場合、UMT は次のサイクルを実行する準備ができています。 次のコマンドの実行をシミュレートします。
シンボル Q t と Q z が一致すると、問題の解決は終了し、UMT は最終状態 U z になります。
UMT の動作プロセスを分析すると、UMT の動作アルゴリズムは、シミュレートされたチューリング マシンがどのような特定の問題を解決するかに依存しないという重要な結論を導き出すことができます。 したがって、UMT コントロール ユニットの構造は、異なるマシンをモデル化する場合でも変わりません。 解決されるタスクには依存しません。 このため、UMT は真の万能マシンであり、その構造を変更することなくあらゆるアルゴリズムを実行できます。
次の UMT コマンドを選択して実行するプロセスはテープ セルの順次列挙に関連するため、UMT の問題を解決するには時間がかかりすぎます。 したがって、チューリングマシンは汎用のものを含めて構築されることはありませんでしたが、その中に現代のコンピューターの類似物を見るのは難しくありません。 したがって、UMT コマンド ゾーンのコマンド システムはマシン プログラムに似ており、シンボル Q t と X t のペアがマシン コマンドのアドレスの役割を果たします。
ただし、チューリング マシンはアルゴリズムを記述するための非常に便利な手段であり、アルゴリズム理論で広く使用されています。
コントロールの質問
ü1.チューリングマシンの構成は何ですか?
ü2.チューリングマシンの構成は何ですか?
ü3. 1 つのチューリング マシンで別のマシンの動作をシミュレートできますか?
チューリング?
ü4.この場合、どのようなアクションが実行されますか?
ü5.万能チューリングマシンの構造を説明してください。
ü6.UMTテープの各領域にはどのような情報が記録されていますか?
ü7.チューリングマシンの指令体系は何ですか?
ü8.UMT ワークサイクルにはどのようなステップが含まれますか?
ü9.「コマンドゾーンの検索」ステップの内容を説明してください。
ü10.「コマンド実行」ステップの内容を説明してください。
ü11.情報処理プロセスはどのような機能を使用していますか
図はグラフのように見えます。

マシンテーブル値
表1
チューリングマシンでの一部の操作
チューリング マシンの動作は、入力データとコマンド システムによって完全に決定されます。 ただし、特定のマシンが問題をどのように解決するかを理解するには、原則として、そのマシンに与えられた種類の意味のある説明が必要です。  。 これらの説明は、多くの場合、ブロック図とチューリング マシンの操作を使用することで、より形式的かつ正確に行うことができます。 関数の構成を思い出してください。
。 これらの説明は、多くの場合、ブロック図とチューリング マシンの操作を使用することで、より形式的かつ正確に行うことができます。 関数の構成を思い出してください。  そして
そして  呼び出された関数
呼び出された関数  を使用すると得られます。
を使用すると得られます。  計算結果に
計算結果に  。 するために
。 するために  これで決まった
これで決まった  、それは必要十分です
、それは必要十分です  に決定されました
に決定されました  、A
、A  に決定されました
に決定されました  .
.
定理1。 もし  そして
そして  チューリングは計算可能か、そしてその合成
チューリングは計算可能か、そしてその合成  チューリング計算も可能です。
チューリング計算も可能です。
させて  - 計算する機械
- 計算する機械  、A
、A  - 計算する機械
- 計算する機械  、およびそれらの状態のセット
、およびそれらの状態のセット  そして
そして  .
.
車の遷移図を作成してみよう  図から
図から  そして
そして  次のように: 最初の頂点を特定します
次のように: 最初の頂点を特定します  機械図
機械図  終端頂点あり
終端頂点あり  機械図
機械図  (コマンド システムの場合、これはコマンド システムが
(コマンド システムの場合、これはコマンド システムが  指揮系統に割り当てられる
指揮系統に割り当てられる  そしてこのために
そしてこのために  チームで
チームで  と置換する
と置換する  )。 () を使用して図を取得します。
)。 () を使用して図を取得します。  ) と述べています。 初期状態
) と述べています。 初期状態  発表します
発表します  そして最後
そして最後  。 表記を簡単にするために、次のように仮定します。
。 表記を簡単にするために、次のように仮定します。  そして
そして  1 つの変数の数値関数。
1 つの変数の数値関数。
させて  決定した。 それから
決定した。 それから  そして
そして
 。 車
。 車  同じ一連の構成を実行しますが、代わりに
同じ一連の構成を実行しますが、代わりに  で開催されます
で開催されます  。 この構成は、マシンの標準的な初期構成です。
。 この構成は、マシンの標準的な初期構成です。  、 それが理由です
、 それが理由です  。 でも、どのチームもそうなので、
。 でも、どのチームもそうなので、  に含まれた
に含まれた  、 それ
、 それ
したがって  。 もし
。 もし  が定義されていない場合、
が定義されていない場合、  または
または  止まらないので車は
止まらないので車は  止まらないでしょう。 それで車は
止まらないでしょう。 それで車は  計算します
計算します  .
.
こうして作られた機械は  それをマシンの構成と呼びます
それをマシンの構成と呼びます  そして
そして  そして指定する
そして指定する  (または
(または  (
( ))、ブロック図でも示されています。
))、ブロック図でも示されています。
チューリングマシンの構成
させて  ,
, ,
, - 同じ外部アルファベットを持つ 3 つのチューリング マシン
- 同じ外部アルファベットを持つ 3 つのチューリング マシン  、内部状態のアルファベット付き
、内部状態のアルファベット付き  ,
, ,
, とプログラム
とプログラム  ,
, ,
, それぞれ。
それぞれ。
構成 車
車  そして
そして  呼ばれた 車T
、そのプログラムは集合の和集合です
呼ばれた 車T
、そのプログラムは集合の和集合です  そして
そして
 、 どこ
、 どこ  から受信した一連のコマンドを示します。
から受信した一連のコマンドを示します。  すべてを置き換える
すべてを置き換える  の上
の上  .
.
チューリングマシンからの分岐
分岐機 ,
, ,
, による
による  、象徴的に
、象徴的に
呼ばれた 車T
、そのプログラムは次のように取得されます。  チームは除外されます
チームは除外されます  そして
そして  のために
のために  、結果のセットが呼び出されます
、結果のセットが呼び出されます  ; それから。
; それから。
万能チューリングマシン
チューリング マシンのコマンド システムは、特定のデバイスの動作の記述としても、プログラムとしても解釈できます。 明確に結果につながる一連の指示。 例を分析するとき、無意識のうちに 2 番目の解釈が受け入れられます。 私たちは、あらゆるチューリング マシンの動作を再現できるメカニズムとして機能します。 誰もがこれを同じように行うだろうという確信 (間違いを犯さなければ、ちなみにチューリング マシンが動作するときにもそれが想定されます) は、本質的にチューリング マシンの動作を再現するアルゴリズムの存在に対する自信です。与えられたプログラムに従ってマシンを動かします。 コマンドシステム。 実際、そのようなアルゴリズムを口頭で説明するのは難しくありません。 その主なアクションは周期的に繰り返され、次の内容で構成されます: 「現在の構成の場合」  コマンド体系の左側でコマンドを検索します
コマンド体系の左側でコマンドを検索します  。 このコマンドの右側が次の形式の場合、
。 このコマンドの右側が次の形式の場合、  、現在の構成に置き換えます
、現在の構成に置き換えます  の上
の上  (構成が判明しました
(構成が判明しました  ); 右側に次のような形がある場合
); 右側に次のような形がある場合  、交換してください
、交換してください  の上
の上  。 アルゴリズムの口頭での説明は不正確である可能性があるため、形式的に説明する必要があります。 チューリング マシンは現在、アルゴリズムの概念を形式化したものとして議論されているため、説明された再生アルゴリズムを実装するチューリング マシンを構築するという問題が生じるのは当然です。 1 つの変数の関数を計算するチューリング マシンの場合、この問題の定式化は次のようになります。 チューリング マシンを構築する
。 アルゴリズムの口頭での説明は不正確である可能性があるため、形式的に説明する必要があります。 チューリング マシンは現在、アルゴリズムの概念を形式化したものとして議論されているため、説明された再生アルゴリズムを実装するチューリング マシンを構築するという問題が生じるのは当然です。 1 つの変数の関数を計算するチューリング マシンの場合、この問題の定式化は次のようになります。 チューリング マシンを構築する  、2 つの変数の関数を計算し、どのマシンでも
、2 つの変数の関数を計算し、どのマシンでも  コマンドシステム付き
コマンドシステム付き  、 もし
、 もし  定義されている(つまり、マシンが
定義されている(つまり、マシンが  初期データで停止する
初期データで停止する  ) そして
) そして  止まらない場合
止まらない場合  止まらない。 このプロパティを持つマシンをすべて呼び出します 万能チューリングマシン。 この定式化を任意の数の変数に一般化することは難しくありません。
止まらない。 このプロパティを持つマシンをすべて呼び出します 万能チューリングマシン。 この定式化を任意の数の変数に一般化することは難しくありません。
汎用マシンを構築するときに発生する最初の問題  、という事実によるものです。
、という事実によるものです。  他のチューリングマシンと同様に、固定されたアルファベットが必要です
他のチューリングマシンと同様に、固定されたアルファベットが必要です  固定された一連の状態
固定された一連の状態  。 したがって、コマンドシステムは、
。 したがって、コマンドシステムは、  および任意のマシンの初期データ
および任意のマシンの初期データ  単に機械のベルトに転写することはできません
単に機械のベルトに転写することはできません  (いつも車があります
(いつも車があります  、アルファベット
、アルファベット  そして
そして  どちらが力に優れているか
どちらが力に優れているか  そして
そして  または単に一致しない)。
または単に一致しない)。
解決策は、次の文字を使用することです。  そして
そして  アルファベットの記号でエンコードされる
アルファベットの記号でエンコードされる  。 させて
。 させて  ,
, 。 私たちは常に次のように仮定します
。 私たちは常に次のように仮定します  そして
そして  (これら 2 つの記号は、数字を扱うマシンのアルファベットには常に含まれています)。 コードを表しましょう
(これら 2 つの記号は、数字を扱うマシンのアルファベットには常に含まれています)。 コードを表しましょう  そして
そして  を通して
を通して  そして
そして  そしてそれらを次のように定義します
そしてそれらを次のように定義します  ; 他の誰かのために
; 他の誰かのために  ; 最終状態用
; 最終状態用 

 、 もし
、 もし 
 。 コード
。 コード  この車の場合
この車の場合  常に長さ (形式) があります
常に長さ (形式) があります  、およびコード
、およびコード  - フォーマット
- フォーマット  。 記号
。 記号  ,
,
 入りましょう
入りましょう  、つまり
、つまり  ,
, ,
, 。 文字コード
。 文字コード  、この単語を構成する文字のコードによって形成され、次のように表します。
、この単語を構成する文字のコードによって形成され、次のように表します。  。 したがって、万能機械の問題の定式化の最終的な改良は、
。 したがって、万能機械の問題の定式化の最終的な改良は、  つまり、どんな車でも
つまり、どんな車でも  そして言葉
そして言葉  アルファベット
アルファベット  .
.
万能チューリングマシンの存在は、命令システムが  どの車でも
どの車でも  元のデバイスの動作の説明として解釈することができます。
元のデバイスの動作の説明として解釈することができます。  、または汎用マシンのプログラムとして
、または汎用マシンのプログラムとして  。 制御システムを設計する現代のエンジニアにとって、この状況は自然なことです。 彼は、あらゆる制御アルゴリズムが、適切な回路を構築することによってハードウェアで実装できること、またはユニバーサル制御コンピュータ プログラムを作成することによってソフトウェアで実装できることをよく知っています。
。 制御システムを設計する現代のエンジニアにとって、この状況は自然なことです。 彼は、あらゆる制御アルゴリズムが、適切な回路を構築することによってハードウェアで実装できること、またはユニバーサル制御コンピュータ プログラムを作成することによってソフトウェアで実装できることをよく知っています。
ただし、普遍的なアルゴリズムデバイスのアイデアは、その実装のための現代の技術的手段(電子工学、物理学)の開発とはまったく無関係であることを認識することが重要です。 固体など)、技術的なものではなく、数学的な事実であり、技術的手段から独立した抽象的な数学用語で記述され、さらに、非常に少数の非常に初歩的な初期概念に基づいています。 特徴的なのは、アルゴリズム理論の基礎的な著作(特にチューリングの著作)が、現代のコンピュータが誕生する前の 30 年代に登場したことです。
この二重の解釈により、2 つのエンジニアリング実装オプションの主な長所と短所が抽象レベルで保持されます。 特定の車  はるかに高速に動作します。 また、機械の制御装置
はるかに高速に動作します。 また、機械の制御装置  非常に面倒です (つまり、状態とコマンドの数が多い)。 ただし、その値は一定であり、一度構築されると、任意の大規模なアルゴリズムを実装するのに適しています。 必要なのは大量のテープだけであり、当然、制御装置よりも安価で構造が簡単であると考えられます。 さらに、アルゴリズムを変更する場合、新しいデバイスを構築する必要はなく、新しいプログラムを作成するだけで済みます。
非常に面倒です (つまり、状態とコマンドの数が多い)。 ただし、その値は一定であり、一度構築されると、任意の大規模なアルゴリズムを実装するのに適しています。 必要なのは大量のテープだけであり、当然、制御装置よりも安価で構造が簡単であると考えられます。 さらに、アルゴリズムを変更する場合、新しいデバイスを構築する必要はなく、新しいプログラムを作成するだけで済みます。